Paper reading-Eagle Exploring The Design Space for Multi- modal LLMs with Mixture of Encoders
nvidia的论文, 主要还是实践训练MLLM上的一堆经验
任务
探究通过使用不同的视觉编码器和分辨率来提高MLLM系统性能的不同设计带来的效果
motivation
- 解读高分辨率的精细视觉信息是MLLM重要的课题,常用的CLIP-ViT 预训练时候的分辨率只有如224*224或者336*336,对OCR等细粒度信息不够好
- 近期研究发现
enhanced visual perception显著减少幻觉和提高性能,许多近期MLLM用了混合视觉编码器- 有扩大视觉编码器的预训练量和参数的
- 有将高分辨率编码器和CLIP融合的
- 也有更复杂的融合和路由,根据任务选用不同编码器,"视觉MoE"的
- 但缺乏对此类方法设计的通用考量, 以及综合性的大benchmark
方法
- 对不同的视觉编码器进行基准测试,寻找更高分辨率自适应的方案
- 对不同的视觉编码器混合策略做同类比较(论文将近期的混合策略归为了CC,SA,LH等几类)
- 寻找多个视觉编码器的最优组合
- 改进pre-alignment和数据混合
增加输入分辨率的做法
- Tiling 将输入分割为子图,CLIP-ViT单独编码
- 直接放大输入分辨率,并对位置编码进行进行插值
Eagle做的实验:
预训练,LLaVA-1.5 + CLIP 基础模型,和LLaVA相同的 595k 图文对,冻结整个模型,只训练projection layer
SFT: 1809k 多模态对话数据
评估:11个任务,包含VQA任务, OCR/文档/图表理解,视觉中心任务,基于知识的任务
结果 - Strong CLIP
-
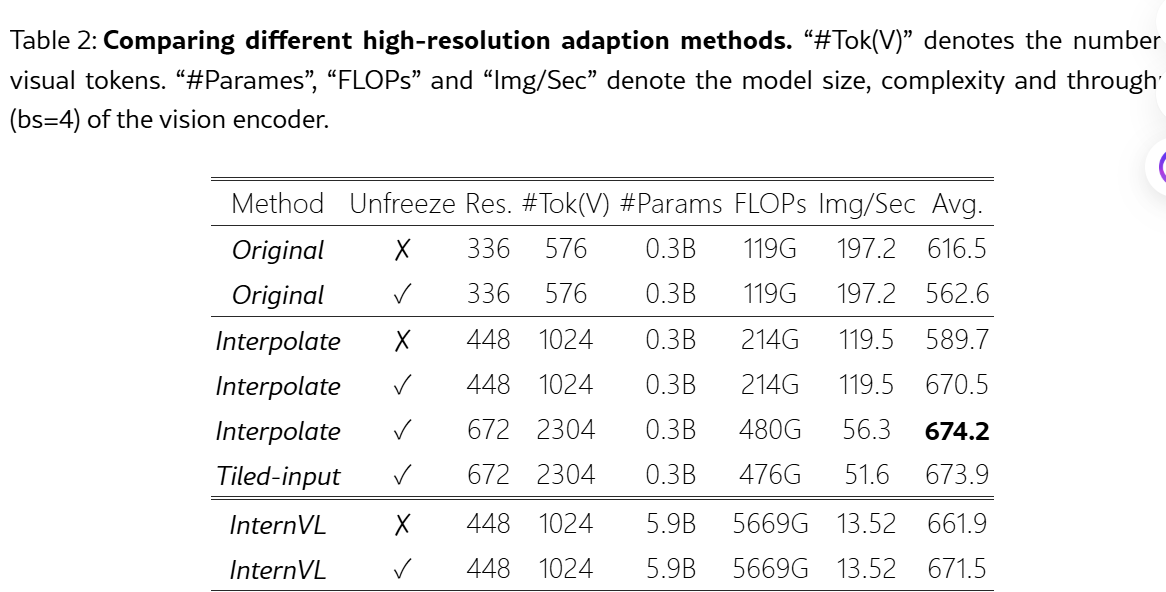
如果插值,需要unfrozen视觉编码器,否则损害性能。这个结论和以前实验不同。
-
输入分辨率和预训练分辨率差越大,插值越掉点
-
672分辨率下,插值和子图方法性能差不多,但是考虑效率的话还是插值更好
-
进行分辨率adaption,300M的CLIP-ViT性能接近6B的InternVL
按照下表,nvidia着重提了448*448+解锁视觉编码器的方案,300M就达到非常接近SOTA的性能了。
Vision Encoder
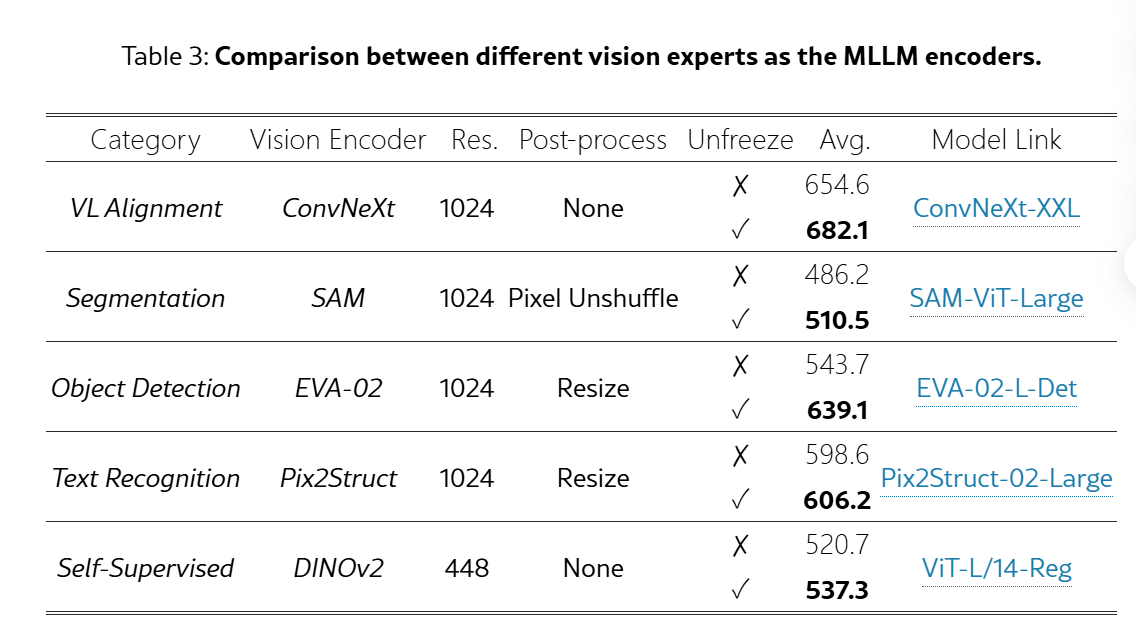
选取了以下的encoder
-
视觉语言对比学习的视觉Encoder,比如CLIP的ViT和OpenCLIP的ConxNeXt;
-
以目标检测为中心的任务预训练的视觉Encoder,EVA-02
-
OCR上训练的Pix2Struct
-
分割上预训练的SAM
-
自监督训练的DINO-V2
对不同预训练的视觉encoder输出的特征图进行resize和插值,使得视觉token数量相同.
结果:
分析:
- 在freeze的情况下他们通常能在和自己预训练任务相近的MLLM benchmark上实现最佳性能。例如来自CLIP的ConvNeXt进行了图文对齐,因此在TextVQA、SQA任务上时所有编码器里表现的最好的。而Text Recognition任务上训练所得的Pix2Struct视觉编码器,在OCR任务上是表现的最好的。
- 当跟随CLIP-ViT高分辨率拓展策略,unfreeze视觉编码器时,基本都能有性能提升,也有反超对应domain上训练的视觉编码器的可能性,例如CLIP-ConvNeXt微调后在OCR上性能超过了Pix2Struct。
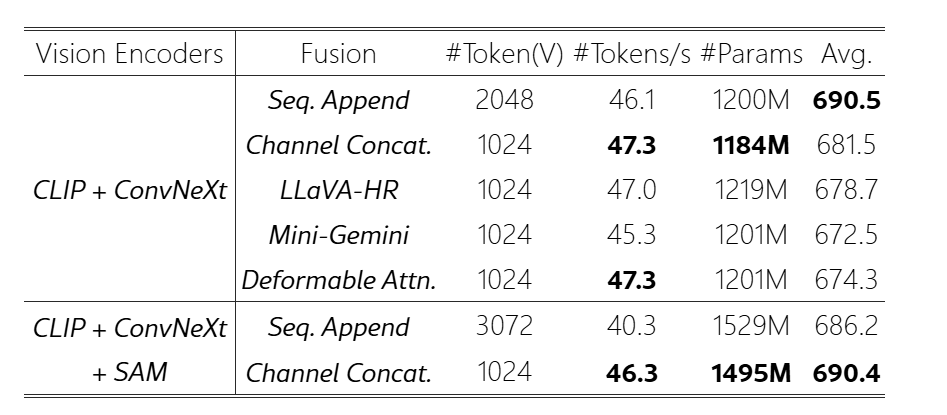
融合策略:

- 序列维度拼接:SA sequence append
- 通道维度拼接:CC concat channel
- LLAVA-HR式:LH 将高分辨率特征使用adapter注入低分辨率特征中,维持序列长度、通道维度不变
- Mini-Gemini式:MG 将高分辨率特征使用local windows cross attention注入到低分辨率的queries中。
- Deformable Attention式:DA 将MG的local windows变成了Deformable Attention
结果:
-
融合策略越复杂,性能的提升似乎越差,简单的SA/CC稳定涨点
-
由于SA需要处理边长的序列长度,所以后面用CC
Pre-Alignment

考虑对其他的视觉专家进行预先的文本模态对齐,再学会去融合不同视觉专家的特征。因此在目前的两阶段MLLM训练框架之前,添加了一个vision-language pre-alignment training阶段,首先使用next-token prediction监督每个视觉专家的特征+各自单独的projector(与LLaVA原始预训练策略不同)训练,让其与一个冻结的较小语言模型对齐。
- 进行一个额外的预先对齐,可以比较好提升MLLM性能。
- 预对齐后,再合并所有的视觉专家,训练projector和encoder
- 虽然在 SFT 期间解冻视觉专家有助于通过更新视觉专家以适应语言模型来提高性能,但预对齐策略更有效地减轻了每位视觉专家的固有偏差,并稳定了训练过程,从而提高了整体性能 (unfreeze + pre-align效果加性)
Fusion choice

采用上述的3阶段训练和最好最简单的Channel concat策略,就可以进一步研究哪种视觉编码器组合最好。组合的策略是依次增加模型视觉编码器的数量,每次的选择基于上一个数量下最好的组合进行进一步添加。四到五个编码器(X4, X5)目前看来就已经比较合适了。
最佳组合是 CLIP 、 ConvNeXt 、 SAM 、 Pix2Struct 和 EVA-02
最终和benchmark的比较

高分辨率的文档任务的展示: 红色baseline失败,蓝色eagle成功

结论
- MLLM训练期间解锁视觉编码器matters
- 设计先进的融合策略并不能较简单的通道级联显露优势
- 更多的视觉专家MoE能带来持续增益,是增强MLLM能力的有效途径
- 视觉专家如果开始时候设计的任务和文本无关(没有对齐),用冻结的LLM进行预对齐(+解锁)后再整体训练能显著提升性能